
Description
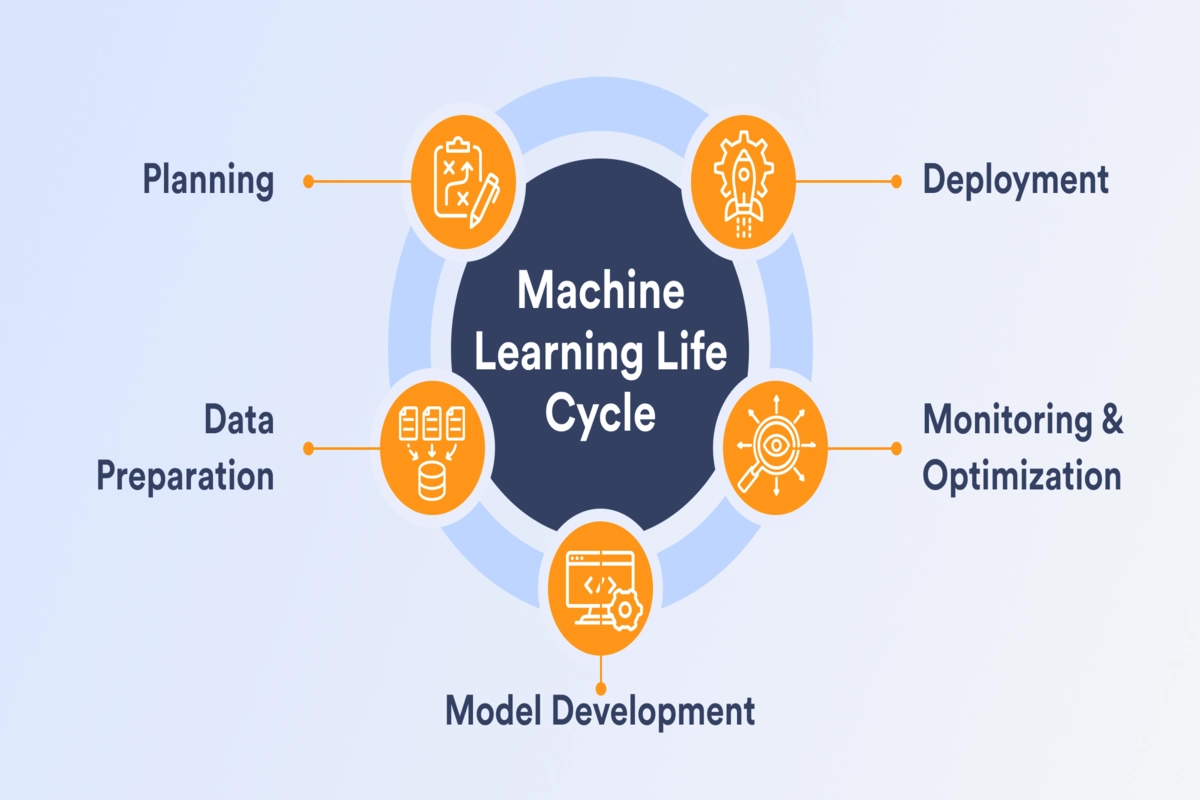
1. Understanding the Problem
-
Define the business or research problem clearly.
-
Determine whether it is:
-
Supervised learning (predict outcomes using labeled data)
-
Unsupervised learning (discover patterns in unlabeled data)
-
Reinforcement learning (learn optimal actions through rewards)
-
-
Identify the success metrics (accuracy, precision, recall, F1-score, RMSE, etc.).
2. Data Collection & Preparation
-
Data Sources: Collect data from databases, APIs, logs, or public datasets.
-
Data Cleaning:
-
Handle missing values.
-
Remove duplicates or irrelevant features.
-
Correct inconsistencies or errors.
-
-
Feature Engineering:
-
Create meaningful features from raw data.
-
Encode categorical variables.
-
Normalize/standardize numerical data.
-
-
Data Splitting:
-
Training set: used to train the model.
-
Validation set: used to tune hyperparameters.
-
Test set: used to evaluate final model performance.
-
3. Model Selection
-
Choose an appropriate algorithm based on problem type and data size:
-
Linear/Logistic Regression: Simple, interpretable.
-
Decision Trees / Random Forest / Gradient Boosting: Handle non-linear relationships well.
-
Support Vector Machines (SVM): Effective in high-dimensional spaces.
-
Neural Networks / Deep Learning: Best for complex patterns, images, text, or sequences.
-
Clustering (K-Means, DBSCAN): For unsupervised grouping.
-
Reinforcement Learning Algorithms: For decision-making tasks.
-
4. Model Training
-
Train the model on the training dataset.
-
Optimize using loss functions relevant to the problem:
-
Regression: Mean Squared Error (MSE)
-
Classification: Cross-Entropy Loss
-
-
Use gradient descent or other optimization algorithms to update model parameters.
5. Model Evaluation
-
Evaluate on the validation/test set to check generalization.
-
Common metrics:
-
Classification: Accuracy, Precision, Recall, F1-Score, ROC-AUC
-
Regression: RMSE, MAE, R² score
-
Clustering: Silhouette Score, Davies–Bouldin Index
-
-
Perform cross-validation to ensure stability.
6. Hyperparameter Tuning
-
Adjust hyperparameters to improve performance:
-
Grid search
-
Random search
-
Bayesian optimization
-
-
Avoid overfitting (model performs well on training but poorly on new data) using regularization and dropout techniques.
7. Model Deployment
-
Convert the trained model into a deployable format:
-
REST API using Flask/FastAPI
-
Integrated into web/mobile apps
-
Cloud deployment (AWS Sagemaker, Google AI Platform, Azure ML)
-
-
Ensure scalability, latency optimization, and security.
8. Monitoring & Maintenance
-
Track performance in production.
-
Retrain with new data if accuracy drops.
-
Monitor for data drift or model bias.
9. Tools & Technologies
-
Programming Languages: Python, R
-
Libraries: scikit-learn, TensorFlow, PyTorch, XGBoost, LightGBM
-
Data Tools: Pandas, NumPy, SQL
-
Visualization: Matplotlib, Seaborn, Plotly


Reviews
There are no reviews yet.